In my previous article, I combined the power of DSPy and LangChain to propose a novel method to optimize prompts in the absence of data. Now, I aim to achieve the same using DSPy only. This article will guide you through the process in two steps: generating synthetic data using DSPy and building and optimizing a DSPy module.
To learn more about DSPy and how to effectively use it, check out these courses:
- Start learning how to program language models using DSPy. Here's the perfect course for that.
- After mastering the basics, explore the advanced use cases of DSPy. Here is the ideal course for that.
Generating Synthetic Data Using DSPy
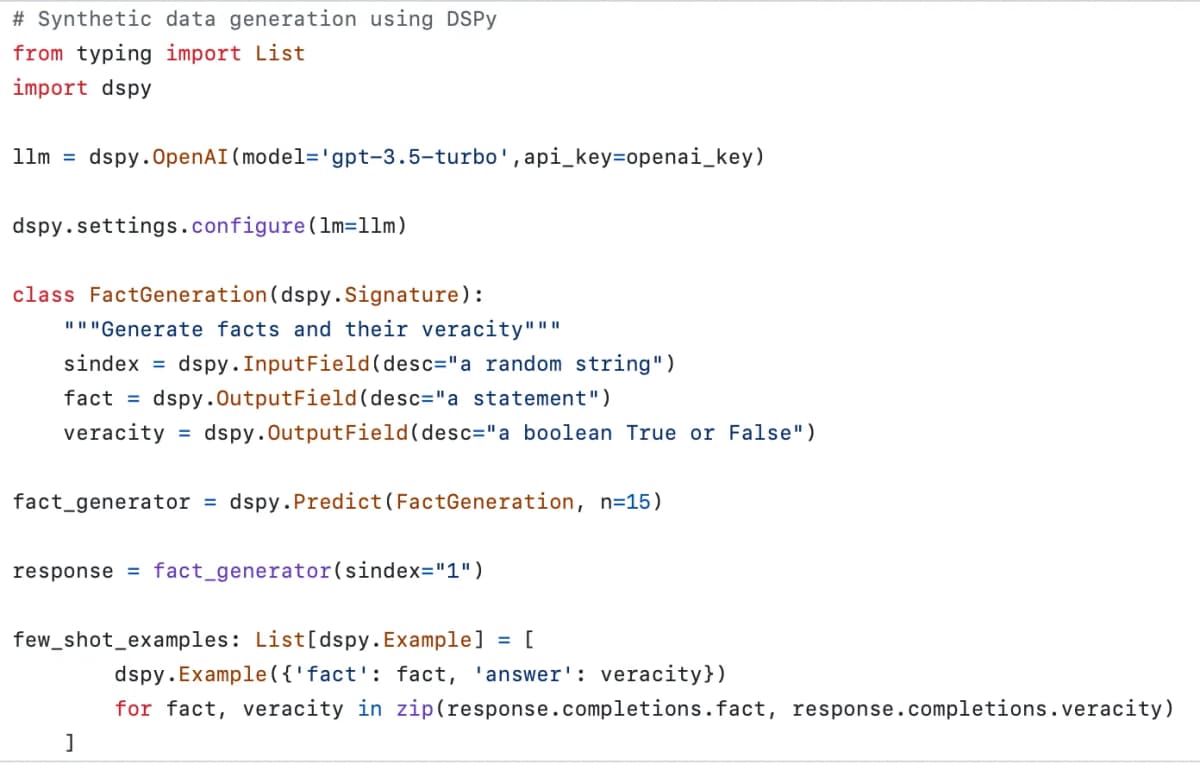
First, I need to generate synthetic data using DSPy. I do so by crafting a class that inherits from dspy.Signature, incorporating a randomized input field and carefully defined output fields that conform to the specific data structure I aim to generate synthetically. This class acts as a blueprint for the synthetic data.
Here is the code to generate synthetic data:
# Synthetic data generation using DSPy
from typing import List
import dspy
llm = dspy.OpenAI(model='gpt-3.5-turbo', api_key=openai_key)
dspy.settings.configure(lm=llm)
class FactGeneration(dspy.Signature):
"""Generate facts and their veracity"""
sindex = dspy.InputField(desc="a random string")
fact = dspy.OutputField(desc="a statement")
veracity = dspy.OutputField(desc="a boolean True or False")
fact_generator = dspy.Predict(FactGeneration, n=15)
response = fact_generator(sindex="1")
few_shot_examples: List[dspy.Example] = [
dspy.Example({'fact': fact, 'answer': veracity})
for fact, veracity in zip(response.completions.fact, response.completions.veracity)
]In this code snippet, I define a class FactGeneration that generates facts and their veracity. I then create a fact_generator object that uses the FactGeneration class to generate 15 synthetic facts. The few_shot_examples list stores the synthetic data in a format that can be used for training and evaluation.
Building and Optimizing the DSPy Module
Once the synthetic data generation is complete, I need to build and optimize my DSPy module. This involves defining evaluation criteria and using the synthetic data generated to compile the module.
Here is the code for synthetic prompt optimization:
# Synthetic Prompt Optimization
from dspy.teleprompt import BootstrapFewShot
from dspy.evaluate import answer_exact_match
text = "Barack Obama was not President of the USA"
# Define the fact as input to the lie detector
trainset = [x.with_inputs('fact') for x in few_shot_examples]
# Define the signature to be used by the lie detector module
class Veracity(dspy.Signature):
"Evaluate the veracity of a statement"
fact = dspy.InputField(desc="a statement")
answer = dspy.OutputField(desc="an assessment of the veracity of the statement")
class LieDetector(dspy.Module):
def __init__(self):
super().__init__()
self.lie_identification = dspy.ChainOfThought(Veracity)
def forward(self, fact):
return self.lie_identification(fact=fact)
teleprompter = BootstrapFewShot(metric=answer_exact_match)
compiled_lie_detector = teleprompter.compile(LieDetector(), trainset=trainset)
response = compiled_lie_detector(fact=text)
print(f"The statement '{text}' is {response.answer}.")One issue I encountered was controlling the variability of synthetic data generated using the pure DSPy approach versus using LangChain or anonLLM. I am open to new ideas for a stronger pure DSPy approach.
Generating Synthetic Datasets Using Pydantic Models
To enhance the flexibility of synthetic data generation, I propose using Pydantic models. This method allows you to define a Pydantic class that inherits from BaseModel and define the schema of the data you want to generate. Then, you pass that to a data generation function that handles the rest.
Here is the code:
from pydantic import BaseModel
import dspy
import random
def synthetic_data_generation(schema_class: BaseModel, sample_size: int):
class_name = f"{schema_class.__name__}Signature"
# Fetch schema information
data_schema = schema_class.model_json_schema()
properties = data_schema['properties']
fields = {
'__doc__': f"Generates the following outputs: {{{', '.join(properties.keys())}}}.",
'sindex': dspy.InputField(desc="a random string")
}
for field_name, field_info in properties.items():
fields[field_name] = dspy.OutputField(desc=field_info.get('description', 'No description'))
signature_class = type(class_name, (dspy.Signature,), fields)
generator = dspy.Predict(signature_class, n=sample_size)
response = generator(sindex=str(random.randint(1, sample_size)))
# Creation of few_shot_examples using dspy.Example
few_shot_examples = [
dspy.Example({
field_name: completion[field_name] for field_name in properties.keys()
}) for completion in response.completions
]
return few_shot_examplesFor more in-depth learning on DSPy, explore the courses offered on Lycee.ai, the first LMS focused on AI content.
Here are two courses that can help you get started:
- Start learning how to program language models using DSPy. Here's the perfect course for that.
- After mastering the basics, explore the advanced use cases of DSPy. Here is the ideal course for that.
Happy coding !!



